Stack Traces With gdb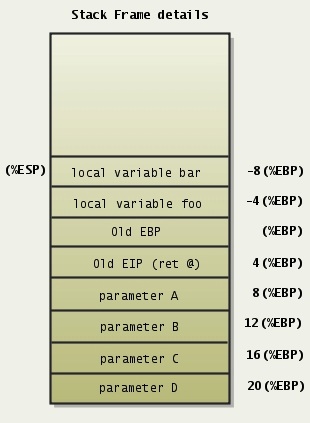
|

Go to Blogger edit html and find these sentences.Now replace these sentences with your own descriptions.This theme is Bloggerized by Lasantha Bandara - Premiumbloggertemplates.com.

Go to Blogger edit html and find these sentences.Now replace these sentences with your own descriptions.This theme is Bloggerized by Lasantha Bandara - Premiumbloggertemplates.com.

Go to Blogger edit html and find these sentences.Now replace these sentences with your own descriptions.This theme is Bloggerized by Lasantha Bandara - Premiumbloggertemplates.com.

Go to Blogger edit html and find these sentences.Now replace these sentences with your own descriptions.This theme is Bloggerized by Lasantha Bandara - Premiumbloggertemplates.com.

Go to Blogger edit html and find these sentences.Now replace these sentences with your own descriptions.This theme is Bloggerized by Lasantha Bandara - Premiumbloggertemplates.com.
Stack Traces With gdb
|

extern void FASTCALL(lock_sock(struct sock *sk)); extern void FASTCALL(release_sock(struct sock *sk));
void fastcall lock_sock(struct sock *sk)
{
might_sleep();
spin_lock_bh(&(sk->sk_lock.slock));
if (sk->sk_lock.owner)
__lock_sock(sk);
sk->sk_lock.owner = (void *)1;
spin_unlock_bh(&(sk->sk_lock.slock));
}
EXPORT_SYMBOL(lock_sock);
void fastcall release_sock(struct sock *sk)
{
spin_lock_bh(&(sk->sk_lock.slock));
if (sk->sk_backlog.tail)
__release_sock(sk);
sk->sk_lock.owner = NULL;
if (waitqueue_active(&(sk->sk_lock.wq)))
wake_up(&(sk->sk_lock.wq));
spin_unlock_bh(&(sk->sk_lock.slock));
}
EXPORT_SYMBOL(release_sock);
static void __lock_sock(struct sock *sk)
{
DEFINE_WAIT(wait);
for(;;) {
prepare_to_wait_exclusive(&sk->sk_lock.wq, &wait,
TASK_UNINTERRUPTIBLE);
spin_unlock_bh(&sk->sk_lock.slock);
schedule();
spin_lock_bh(&sk->sk_lock.slock);
if(!sock_owned_by_user(sk))
break;
}
finish_wait(&sk->sk_lock.wq, &wait);
}
static void __release_sock(struct sock *sk)
{
struct sk_buff *skb = sk->sk_backlog.head;
do {
sk->sk_backlog.head = sk->sk_backlog.tail = NULL;
bh_unlock_sock(sk);
do {
struct sk_buff *next = skb->next;
skb->next = NULL;
sk->sk_backlog_rcv(sk, skb);
/*
* We are in process context here with softirqs
* disabled, use cond_resched_softirq() to preempt.
* This is safe to do because we've taken the backlog
* queue private:
*/
cond_resched_softirq();
skb = next;
} while (skb != NULL);
bh_lock_sock(sk);
} while((skb = sk->sk_backlog.head) != NULL);
}
#define bh_lock_sock(__sk) spin_lock(&((__sk)->sk_lock.slock)) #define bh_unlock_sock(__sk) spin_unlock(&((__sk)->sk_lock.slock))
#define spin_lock_bh(lock) _spin_lock_bh(lock)
void __lockfunc _spin_lock(spinlock_t *lock) __acquires(spinlock_t); void __lockfunc _spin_lock_bh(spinlock_t *lock) __acquires(spinlock_t);
#define _spin_lock_bh(lock) __LOCK_BH(lock)
#define _spin_lock(lock) __LOCK(lock)
#define __LOCK(lock) \
do { preempt_disable(); __acquire(lock); (void)(lock); } while (0)
#define __LOCK_BH(lock) \
do { local_bh_disable(); __LOCK(lock); } while (0)
#define __LOCK_IRQ(lock) \
do { local_irq_disable(); __LOCK(lock); } while (0)
#define __LOCK_IRQSAVE(lock, flags) \
do { local_irq_save(flags); __LOCK(lock); } while (0)
#define __UNLOCK(lock) \
do { preempt_enable(); __release(lock); (void)(lock); } while (0)
#define __UNLOCK_BH(lock) \
do { preempt_enable_no_resched(); local_bh_enable(); __release(lock); (void)(lock); } while (0)
#define __UNLOCK_IRQ(lock) \
do { local_irq_enable(); __UNLOCK(lock); } while (0)
#define __UNLOCK_IRQRESTORE(lock, flags) \
do { local_irq_restore(flags); __UNLOCK(lock); } while (0)
#define spin_lock(lock) _spin_lock(lock
by linuxfoundation.org





sudo add-apt-repository ppa:pidgin-developers/ppa sudo apt-get update && sudo apt-get upgradeIf you are using Pidgin to connect to your MSN messenger, you will probably receive the SSL certificate error message. it’s kinda irritating and prevents you from connecting to your MSN account. Here’s the fix.






1 | sudo apt-get install wine ttf-mscorefonts-installer |
1 | winecfg |
1 | wget http://www.kegel.com/wine/winetricks |
2 | sh winetricks msxml6 gdiplus gecko vcrun2005sp1 vcrun2008 msxml3 atmlib |
| Copy the following folders/files from Windows | and | Paste to Ubuntu |
| C:\Program Files\Adobe\ | -> | $HOME/.wine/drive_c/Program Files/Adobe |
| C:\Program Files\Common Files\Adobe | -> | $HOME/.wine/drive_c/Program Files/Common Files/Adobe |
| C:\Documents and Settings\$USER\Application Data\Adobe | -> | $HOME/.wine/drive_c/users/$USER/Applications Data/Adobe |
| C:\windows\system32\odbcint.dll | -> | $HOME/.wine/drive_c/windows/system32/odbcint.dll |
1 | wine regedit adobe.reg |


gpg –keyserver keyserver.ubuntu.com –recv 3E5C1192
gpg –export –armor 3E5C1192 | sudo apt-key add -
sudo apt-get update
The sheer existence of black hat SEO techniques must be acknowledged for several reasons.As Rishi Lakhani noted on his new SEO blog: You need it at least to know what to avoid or to know how competitors who perform worse than you still manage to outrank your site.
The good news is: Most black hat SEO techniques can be used in a clean, ethical white hat way as well.They are like knives: You can slice bread with a knife but you can kill with it as well. It’s your decision how you use the knife. Also consider the problem with overall perception of the SEO industry. Your hat can be whiter than snow and still people will treat you as the guy with the virtual knife.
Personally I think black hat SEO is for the weak.The black hat logic goes: When you can’t win the game you have to cheat. It’s the same dilemma as in sports though: When everybody cheats how are you going to win? That’s why reputable and successful SEO experts don’t have to use it.





{kind=link}